
Scientists build supersized sets of biological data to better treat diseases and reveal the secrets to youth by mapping the body at the single-cell level.
Scientists at Sanford Burnham Prebys are investigating the inner workings of our bodies and the trillions of cells within them at a level of detail that few futurists could have predicted.
“The scale of the data we can generate and analyze has certainly exploded,” says Yu Xin (Will) Wang, PhD, assistant professor in the Development, Aging and Regeneration Program at Sanford Burnham Prebys. “When I was a graduate student, I would take about a hundred pictures for my experiment and spend weeks manually classifying certain characteristics of the imaged cells.”
“Now, a single experiment would capture probably hundreds of thousands of images and study the gene and protein expression patterns of millions of individual cells.”
The Wang lab specializes in advanced spatial multi-omic analyses that capture the location of cells, proteins and other molecules in the body. Wang uses spatial multi-omics to explore how dysfunctional autoimmune responses—when the immune system attacks the body’s own tissues—can interfere with its ability to repair and regenerate. As well as being relevant to disease, autoimmune responses also play a role in “inflammaging,” the low-level, chronic inflammation that occurs with age. Inflammaging is thought to contribute to many of the physical signs of aging.
“My team thinks about diseases from the perspective of how cells behave in response to changes in the body,” says Wang. “We’re interested in how interactions between the immune and peripheral nervous systems change as people age and make us susceptible to frailty and disease.”

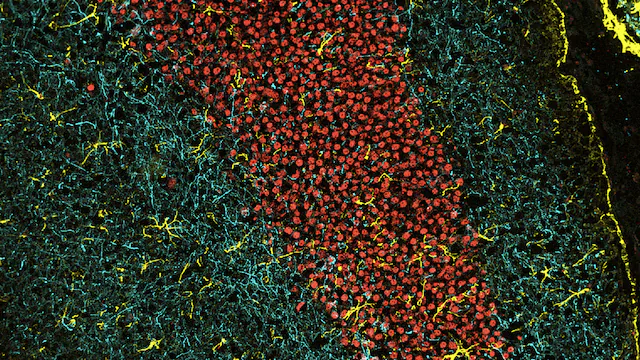
A spectrum of immune cells being studied by Will Wang’s lab at Sanford Burnham Prebys. Image courtesy of postdoctoral associate Beatrice Silvestri, PhD.

Yu Xin (Will) Wang, PhD, is an assistant professor in the Development, Aging and Regeneration Program at Sanford Burnham Prebys.
This spatial multi-omics approach is helping scientific teams across the world on projects to understand how the body works at the cellular level. Efforts such as the Human Cell Atlas and the Human BioMolecular Atlas Program seek to develop a cellular map of the human body. Researchers at Sanford Burnham Prebys are now using these tools to map complex diseases including cancer and degenerative conditions such as muscular dystrophy and ischemic injuries. Wang is also working to map cellular changes in aging through the San Diego Tissue Mapping Center of the Cellular Senescence Network (SenNet), a collaborative effort led by Peter D. Adams, PhD, director of, and professor in, the Institute’s Cancer Genome and Epigenetics Program and Bing Ren, PhD, professor of Cellular and Molecular Medicine at UC San Diego.
“Integrating multiple types of -omics data can give us a much more comprehensive picture as we study health and disease,” notes Wang. Each additional layer of imaging and sequencing data adds more complexity to how Wang and his peers process and analyze their results. This has driven Wang and his colleagues to develop computational algorithms and AI tools to find patterns and novel translatable targets from these “big data” experiments.
Wang credits San Diego-based biotechnology company Illumina for playing a major role by creating next-generation sequencing technology that improved the speed and accuracy of genome sequencing. The cost of sequencing steadily declined after Illumina launched the Genome Analyzer platform in 2007, making this research method more accessible to scientists at Sanford Burnham Prebys and around the globe.
A series of additional technology platforms and research disciplines have followed, allowing scientists to study other parts of biological systems in similarly exhaustive detail. These include epigenomics, transcriptomics, proteomics and metabolomics. Scientists are now able to incorporate more than one of these levels of inquiry into an experiment, which is known as multi-omics.
Connections in the brain photographed during experiments at the Institute.
Image courtesy of postdoctoral associate Sara Ancel, PhD, and Annanya Sethiya, MS, research associate II.
“The amount of information you get back from these sequencing platforms, as well as the application of highly multiplexed biomolecular imaging, has exponentially increased, which really helps us to resolve what we couldn’t before to better understand the genetic regulation of cells and diseases,” says Wang. “The most challenging part is the work to derive the meaning from these massive amounts of information. Thankfully, that’s also the most fun part of what we do.”
Programming in a Petri Dish, an 8-part series
How artificial intelligence, machine learning and emerging computational technologies are changing biomedical research and the future of health care
- Part 1 – Using machines to personalize patient care. Artificial intelligence and other computational techniques are aiding scientists and physicians in their quest to prescribe or create treatments for individuals rather than populations.
- Part 2 – Objective omics. Although the hypothesis is a core concept in science, unbiased omics methods may reduce attachments to incorrect hypotheses that can reduce impartiality and slow progress.
- Part 3 – Coding clinic. Rapidly evolving computational tools may unlock vast archives of untapped clinical information—and help solve complex challenges confronting health care providers.
- Part 4 – Scripting their own futures. At Sanford Burnham Prebys Graduate School of Biomedical Sciences, students embrace computational methods to enhance their research careers.
- Part 5 – Dodging AI and computational biology dangers. Sanford Burnham Prebys scientists say that understanding the potential pitfalls of using AI and other computational tools to guide biomedical research helps maximize benefits while minimizing concerns.
- Part 6 – Mapping the human body to better treat disease. Scientists synthesize supersized sets of biological and clinical data to make discoveries and find promising treatments.
- Part 7 – Simulating science or science fiction? By harnessing artificial intelligence and modern computing, scientists are simulating more complex biological, clinical and public health phenomena to accelerate discovery.
- Part 8 – Acceleration by automation. Increases in the scale and pace of research and drug discovery are being made possible by robotic automation of time-consuming tasks that must be repeated with exhaustive exactness.


